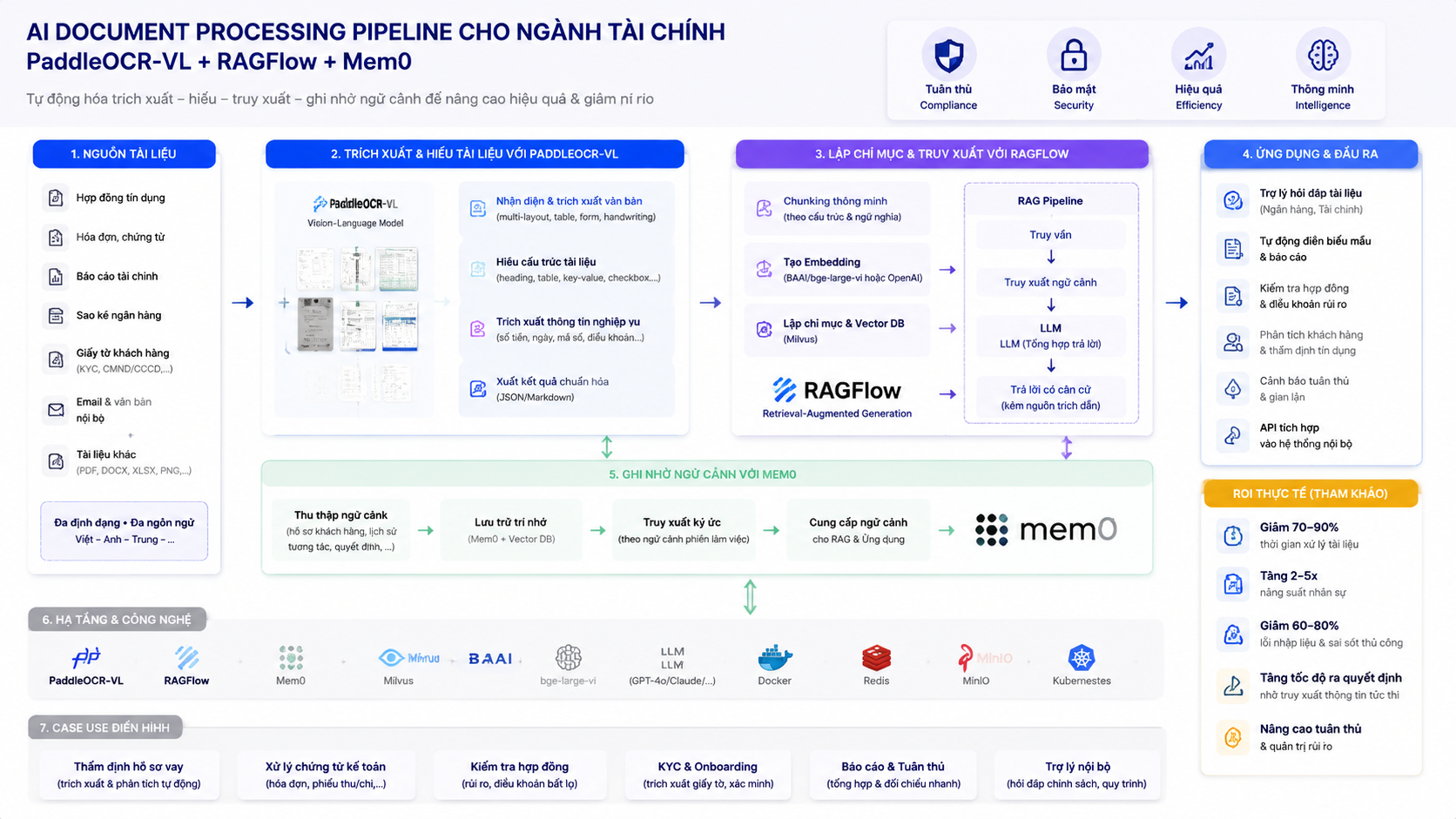

Trong bối cảnh số hóa mạnh mẽ, PaddleOCR‑VL, RAGFlow và Mem0 trở thành các thành phần cốt lõi để xây dựng một AI Document Processing Pipeline hiệu quả cho ngành tài chính. Bài viết này đi sâu phân tích cách những công nghệ này phối hợp với nhau, giải quyết nhu cầu trích xuất thông tin, truy vấn tài liệu và nâng cao giá trị dữ liệu tài chính, đồng thời minh họa cách đo lường ROI thực tế khi triển khai giải pháp tự động hóa tài liệu quy mô doanh nghiệp tài chính.
Tổng quan về Document Processing Pipeline trong ngành tài chính
Trong tài chính, lượng dữ liệu dạng văn bản như báo cáo, hóa đơn, hợp đồng hay bảng tính là khổng lồ và phức tạp. Quy trình xử lý tài liệu thủ công không chỉ tốn thời gian mà còn dễ xảy ra sai sót. Do vậy, xây dựng một pipeline tự động với AI giúp doanh nghiệp giảm chi phí vận hành, tăng tốc độ xử lý và đảm bảo độ chính xác cao hơn.
Thách thức xử lý tài liệu trong tài chính
Ngành tài chính phải đối mặt với nhiều loại tài liệu khác nhau: tài liệu quét từ giấy, PDF đa trang, bảng biểu phức tạp, chữ viết tay và các biểu mẫu không theo chuẩn. Những thách thức này đòi hỏi công nghệ OCR (Optical Character Recognition) tiên tiến và khả năng hiểu ngữ cảnh tài liệu để trích xuất dữ liệu có ý nghĩa. Nếu không có một pipeline chuẩn mực, doanh nghiệp dễ gặp rủi ro trong tuân thủ quy định và phân tích sai số liệu quan trọng. Nguồn tham khảo: Centrix.
Các thành phần chính của một AI Document Processing Pipeline
- Nhận dạng ký tự và cấu trúc tài liệu: OCR/Vision‑Language Models xử lý hình ảnh và văn bản.
- Trích xuất và chuẩn hóa thông tin: Phân loại trường dữ liệu, bảng biểu, mục tiêu kinh doanh.
- Lưu trữ và truy vấn thông tin: Hệ thống tìm kiếm ngữ nghĩa và indexing.
- Giao diện truy vấn: Công cụ tương tác cho nhân viên nội bộ hoặc API tích hợp với ứng dụng khác.
Một pipeline hiệu quả phải đảm bảo các bước này phối hợp mượt mà, phản hồi nhanh và có khả năng mở rộng khi dữ liệu tăng trưởng.
Giải thích công nghệ PaddleOCR‑VL

PaddleOCR‑VL là một hệ thống dựa trên mô hình Vision‑Language Model (VLM) được thiết kế để đọc và hiểu văn bản trong hình ảnh và tài liệu PDF. Trong ngành tài chính, việc trích xuất chính xác dữ liệu từ tài liệu phức tạp là rất quan trọng, và PaddleOCR‑VL nổi trội ở khả năng nhận dạng đa ngôn ngữ, hỗ trợ bảng biểu và định dạng phức tạp mà nhiều OCR truyền thống gặp khó khăn.
PaddleOCR‑VL là gì và ưu điểm chính
PaddleOCR‑VL kế thừa sức mạnh từ mô hình nhận dạng ký tự hiện đại và mô hình ngôn ngữ, giúp không chỉ nhận diện chữ mà còn gắn ngữ cảnh cho từng phân đoạn văn bản. Điều này đặc biệt hữu ích khi xử lý các mục như tên tài sản, số tài khoản, hay các mục định danh tài chính có cấu trúc phức tạp. So với các giải pháp OCR truyền thống chỉ đọc ký tự, PaddleOCR‑VL đem lại độ chính xác cao hơn cho các định dạng tài liệu đa dạng.
Ví dụ, khi trích xuất bảng số liệu trong báo cáo tài chính, mô hình có thể nhận ra mối quan hệ giữa tiêu đề cột và giá trị dữ liệu thay vì chỉ đọc từng ký tự rời rạc, giúp hệ thống downstream xử lý dữ liệu hiệu quả hơn.
Kiến trúc và cách hoạt động của PaddleOCR‑VL
PaddleOCR‑VL kết hợp module xử lý hình ảnh với mô hình ngôn ngữ để tạo ra biểu diễn ngữ nghĩa phong phú hơn. Quy trình gồm bước tiền xử lý ảnh, nhận dạng ký tự, phân đoạn cấu trúc tài liệu và gán nhãn semantic. Bằng cách này, các trường thông tin cần trích xuất như ngày tháng, số tiền, định danh… được đánh dấu chính xác và sẵn sàng cho bước xử lý tiếp theo như lưu vào cơ sở dữ liệu hoặc chuyển tới module truy vấn.
Cài đặt và tích hợp cơ bản PaddleOCR‑VL
Để triển khai PaddleOCR‑VL, đội kỹ thuật cần chuẩn bị môi trường Python và GPU nếu xử lý khối lượng lớn tài liệu. Sau khi cài đặt thư viện và mô hình, các API có thể được gọi để xử lý batch tài liệu hoặc tích hợp vào hệ thống backend. Điểm quan trọng là cần chuẩn bị pipeline tiền xử lý hình ảnh (chuyển ảnh xám, cân bằng sáng, loại nhiễu) để tối ưu hiệu suất nhận dạng.
Tích hợp RAGFlow cho truy vấn và truy xuất thông tin

Khi đã trích xuất văn bản với PaddleOCR‑VL, bước tiếp theo là xây dựng khả năng truy vấn thông tin hiệu quả. Đó là lúc RAGFlow xuất hiện như một công cụ RAG (Retrieval‑Augmented Generation) giúp kết hợp dữ liệu tài liệu đã được OCR với mô hình ngôn ngữ lớn để trả lời truy vấn hoặc tóm tắt nội dung.
RAGFlow là gì trong bối cảnh RAG (Retrieval‑Augmented Generation)
RAGFlow là framework mã nguồn mở hỗ trợ xây dựng pipeline RAG, trong đó phần retrieval sử dụng kỹ thuật embedding và chỉ mục để tìm kiếm các đoạn tài liệu liên quan, sau đó phần generation dùng mô hình ngôn ngữ để tạo phản hồi dựa trên ngữ cảnh tìm được. Với tài liệu tài chính, RAGFlow giúp trả lời các câu hỏi như “tổng doanh thu quý 2 là bao nhiêu” bằng cách tìm và trích xuất dữ liệu liên quan trong corpus tài liệu OCR đã được xử lý.
Quy trình tích hợp RAGFlow với đầu ra từ OCR
Đầu tiên, văn bản đầu ra từ PaddleOCR‑VL được chuẩn hóa, xóa các ký tự nhiễu và chia thành các đoạn nhỏ để indexing. Các đoạn này sau đó được ánh xạ sang embedding vector để lưu vào chỉ mục tìm kiếm. Khi người dùng gửi truy vấn, RAGFlow sử dụng truy vấn embedding để tìm các đoạn liên quan, rồi sử dụng mô hình ngôn ngữ để sinh kết quả chính xác hơn.
Cách chuẩn hóa và chunk dữ liệu tài liệu cho RAGFlow
Chuẩn hóa văn bản bao gồm chuyển nội dung về dạng unicode tiêu chuẩn, loại bỏ ký tự đặc biệt không cần thiết, và chia văn bản thành các chunk có độ dài phù hợp để embedding. Việc chunk đúng kích thước giúp cân bằng giữa độ chính xác tìm kiếm và thời gian xử lý.
Kiến trúc tổng thể Pipeline: Từ Scan đến Insight

Để một AI Document Processing Pipeline hoạt động trơn tru, việc thiết kế kiến trúc end‑to‑end đóng vai trò then chốt. Kiến trúc này phải đảm bảo dòng dữ liệu từ lúc nhập tài liệu thô đến khi tạo ra insight có thể sử dụng được cho người dùng hoặc hệ thống downstream là liền mạch, hiệu quả và dễ bảo trì.
Kiến trúc end‑to‑end
Một pipeline hiệu quả thường bao gồm các thành phần: thu nhận tài liệu (scan/PDF upload), tiền xử lý hình ảnh (lọc nhiễu, định hình trang), nhận dạng văn bản với PaddleOCR‑VL, lưu trữ và indexing để truy vấn với RAGFlow, và cuối cùng là lớp memory (Mem0) để hỗ trợ truy vấn liên tục và bảo lưu ngữ cảnh quan trọng. Mỗi thành phần phải có API rõ ràng và cơ chế giám sát lỗi để dễ dàng điều chỉnh khi cần.
Các bước dữ liệu chảy qua Pipeline
- Thu thập tài liệu: Tài liệu quét, upload qua hệ thống hoặc lấy từ kho lưu trữ cũ.
- Tiền xử lý hình ảnh: Chuẩn hoá kích thước, loại nhiễu, điều chỉnh độ tương phản giúp OCR chính xác hơn.
- Nhận dạng văn bản: PaddleOCR‑VL đọc ký tự và cấu trúc tài liệu để tạo ra văn bản có cấu trúc.
- Index và embedding: Chia văn bản thành đoạn nhỏ, mã hóa thành vector để lưu vào chỉ mục tìm kiếm semantic.
- Truy vấn và sinh đáp: RAGFlow nhận truy vấn, tìm đoạn liên quan và tạo phản hồi dựa trên ngữ cảnh.
- Bảo lưu ngữ cảnh: Mem0 lưu thông tin quan trọng để hỗ trợ các truy vấn tiếp theo liên quan cùng bộ tài liệu.
Ví dụ luồng xử lý tài liệu tài chính
Giả sử doanh nghiệp có hàng nghìn báo cáo tài chính PDF hàng quý. Tài liệu được upload lên hệ thống, tiền xử lý loại bỏ nhiễu và xoay trang cần thiết. PaddleOCR‑VL trích xuất nội dung, sau đó RAGFlow cho phép người dùng hỏi về “tỷ lệ nợ trên vốn chủ sở hữu” và nhận được câu trả lời dựa trên các đoạn tài liệu liên quan. Khi người dùng tiếp tục đặt câu hỏi về các chỉ số liên quan, Mem0 giúp hệ thống nhớ chủ đề đang quan tâm, cung cấp phản hồi liền mạch hơn mà không phải tái tìm kiếm từ đầu.
Tối ưu hiệu suất và ROI thực tế

Triển khai một AI Document Pipeline không chỉ là tích hợp công nghệ, mà phải thể hiện giá trị kinh tế rõ rệt. Việc đo lường ROI giúp doanh nghiệp quyết định đầu tư tiếp hay mở rộng quy mô.
Những chỉ số đo ROI khi triển khai AI Document Processing
- Thời gian xử lý: So sánh thời gian từ lúc nhận tài liệu đến khi sẵn sàng truy vấn giữa quy trình thủ công và pipeline tự động.
- Độ chính xác: Tỷ lệ lỗi nhận dạng và trích xuất dữ liệu so với benchmark trước khi triển khai.
- Hiệu quả kinh doanh: Lượng thời gian tiết kiệm được cho nhân sự, giảm chi phí vận hành.
Khi những chỉ số này được cải thiện rõ rệt sau khi dùng PaddleOCR‑VL, RAGFlow và Mem0, doanh nghiệp có thể tính toán giá trị tương đương tiền từ việc tiết kiệm thời gian và lỗi giảm thiểu.
So sánh chi phí với các giải pháp OCR/Document AI khác
So sánh chi phí đầu tư ban đầu và chi phí vận hành định kỳ với các giải pháp thương mại sẵn có giúp doanh nghiệp thấy rõ lợi thế cạnh tranh. Các mô hình mã nguồn mở như PaddleOCR‑VL và RAGFlow cho phép giảm lệ thuộc vào nhà cung cấp dịch vụ bên ngoài, kiểm soát chi phí linh hoạt hơn, đặc biệt khi quy mô tài liệu tăng lên.
Các điểm cần lưu ý khi triển khai trong doanh nghiệp tài chính
Trong doanh nghiệp tài chính, yếu tố tuân thủ và bảo mật dữ liệu luôn được đặt lên hàng đầu. Do đó, pipeline cần đáp ứng các tiêu chuẩn nội bộ và quy định pháp lý, dữ liệu phải được mã hóa khi lưu trữ và truyền tải. Đội ngũ kỹ thuật nên thực hiện kiểm thử an ninh định kỳ để đảm bảo không có lỗ hổng bị khai thác.
Trường hợp thực tế và demo code mẫu

Để minh hoạ cách tích hợp các thành phần, dưới đây là khái quát logic cho phần demo:
Ví dụ demo tích hợp PaddleOCR‑VL và RAGFlow
Đoạn code mẫu (logic) cho thấy cách gọi API PaddleOCR‑VL để nhận dạng văn bản từ PDF, sau đó chuẩn hoá và lưu vào hệ thống indexing của RAGFlow để phục vụ truy vấn semantic. Mặc dù mỗi doanh nghiệp có cấu trúc dữ liệu khác nhau, logic chung này giúp đội kỹ thuật nhanh chóng bắt đầu thử nghiệm.
Demo sử dụng Mem0 để duy trì memory
Mem0 được triển khai như một lớp lưu giữ các ngữ cảnh quan trọng giữa các phiên truy vấn. Khi người dùng hỏi một loạt câu hỏi liên quan, Mem0 giúp mô hình ghi nhớ các chủ đề chính, tránh việc phải tái xây dựng ngữ cảnh từ đầu mỗi lần, giúp phản hồi nhanh và tự nhiên hơn.
Các câu hỏi thường gặp (FAQ)
Pipeline AI Document Processing là gì?
Đây là chuỗi các bước tự động từ nhận diện văn bản, trích xuất dữ liệu, lưu trữ semantic đến truy vấn thông tin và cung cấp phản hồi dựa trên ngữ cảnh, đặc biệt hữu ích trong ngành tài chính với lượng tài liệu lớn.
Tại sao nên dùng PaddleOCR‑VL thay vì OCR truyền thống?
PaddleOCR‑VL không những nhận dạng ký tự mà còn hiểu cấu trúc và ngữ cảnh trong tài liệu phức tạp, giúp giảm lỗi và cải thiện chất lượng dữ liệu đầu ra.
Mem0 giúp gì cho hệ thống?
Mem0 là lớp nhớ thông minh giúp giữ ngữ cảnh qua các truy vấn tiếp nối, tăng tốc độ phản hồi và độ chính xác khi người dùng đặt chuỗi câu hỏi liên quan.
Kết luận và bước tiếp theo
Việc triển khai một AI Document Processing Pipeline sử dụng PaddleOCR‑VL, RAGFlow và Mem0 mang lại lợi ích rõ rệt cho doanh nghiệp tài chính: giảm tải công việc thủ công, cải thiện độ chính xác dữ liệu và nâng cao hiệu quả truy vấn. Khi đo lường ROI, doanh nghiệp thấy được giá trị kinh tế từ việc tự động hóa quy trình này so với cách làm truyền thống.
Đối với những doanh nghiệp quan tâm thử nghiệm giải pháp này, bước tiếp theo là xác định bộ tài liệu mẫu để thử nghiệm, đo lường hiệu suất ban đầu và điều chỉnh pipeline cho phù hợp với yêu cầu nội bộ.
Nếu bạn muốn khám phá cách các công cụ này áp dụng vào quy trình của mình, hãy bắt đầu với những tài liệu thực tế và xây dựng một nguyên mẫu để đánh giá rõ nhất khả năng cải thiện hiệu suất và chi phí vận hành.



