
Doanh nghiệp đang dùng AI nhiều hơn cho chăm sóc khách hàng, đào tạo nội bộ, viết tài liệu, phân tích hợp đồng và tra cứu quy trình. Nhưng càng đưa nhiều dữ liệu vào AI, câu hỏi bảo mật càng trở nên nghiêm túc: tài liệu nội bộ có bị gửi sang bên thứ ba không, ai có quyền xem lịch sử chat, và doanh nghiệp có kiểm soát được nơi dữ liệu được xử lý hay không?
Tóm tắt meta-worthy: Tự host AnythingLLM, Ollama trên VPS giúp doanh nghiệp xây dựng một ChatGPT riêng có khả năng hỏi đáp tài liệu nội bộ, kiểm soát hạ tầng và giảm phụ thuộc vào API AI cloud.
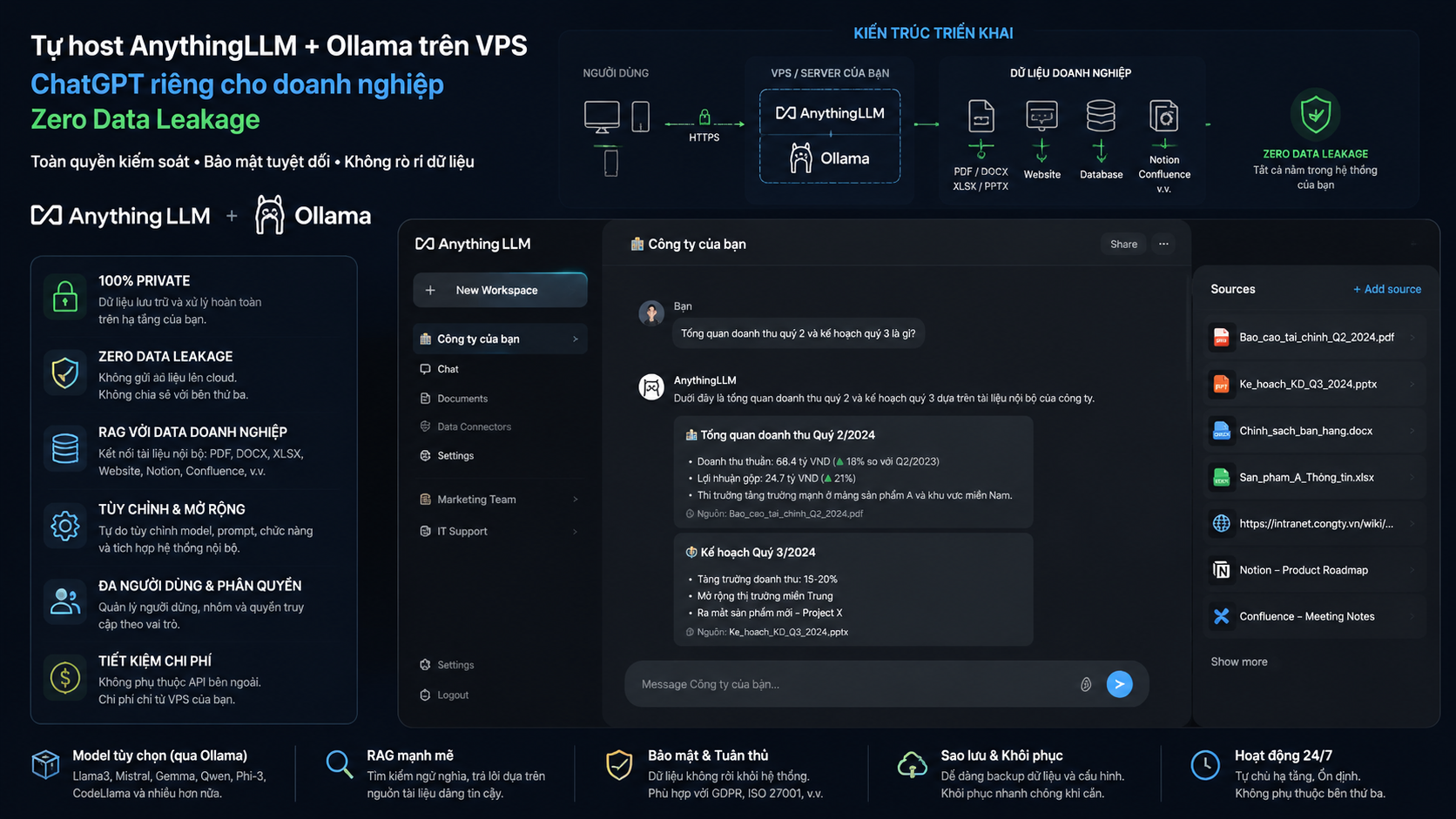
Về bản chất, đây là mô hình triển khai AI nội bộ: AnythingLLM đóng vai trò giao diện chat, quản lý workspace và xử lý RAG; Ollama chạy mô hình ngôn ngữ cục bộ; VPS là hạ tầng để đội ngũ truy cập tập trung. Khi cấu hình đúng, dữ liệu không cần rời khỏi máy chủ do doanh nghiệp kiểm soát. Tuy nhiên, “zero data leakage” không nên hiểu là an toàn tuyệt đối, mà là mục tiêu kiến trúc: giảm tối đa việc đưa dữ liệu nhạy cảm ra ngoài và quản trị hệ thống theo chuẩn bảo mật.
Từ góc nhìn triển khai thực tế, CentriX.digital xem mô hình này như một bước tiến tự nhiên cho doanh nghiệp đã quen dùng ChatGPT, Claude, Gemini, Perplexity hoặc Copilot, nhưng bắt đầu cần một lớp AI riêng cho dữ liệu nội bộ. CentriX không chỉ bán phần mềm, mà giúp khách hàng rút ngắn khoảng cách giữa ý tưởng và hệ thống vận hành thật.
1. Tổng quan giải pháp AnythingLLM và Ollama
1.1. AnythingLLM là gì?
AnythingLLM là một ứng dụng AI all-in-one cho phép doanh nghiệp tạo workspace, nạp tài liệu, xây dựng luồng hỏi đáp theo kiểu RAG và kết nối với nhiều backend LLM khác nhau. Theo tài liệu chính thức của AnythingLLM, nền tảng này tập trung vào RAG, AI Agents và triển khai theo hướng ít phức tạp về hạ tầng.
Điểm đáng chú ý của AnythingLLM nằm ở cách tổ chức tri thức. Thay vì để toàn bộ tài liệu công ty nằm trong một kho lẫn lộn, doanh nghiệp có thể tách workspace theo phòng ban hoặc mục đích: Sales, CSKH, HR, tài liệu sản phẩm, chính sách nội bộ, quy trình vận hành. Mỗi workspace có ngữ cảnh riêng, giúp chatbot trả lời sát phạm vi hơn và giảm nhiễu thông tin.
Ví dụ, một đội sales có thể đưa bảng giá, chính sách bảo hành, catalogue sản phẩm và kịch bản tư vấn vào một workspace riêng. Khi nhân viên hỏi “khách hàng doanh nghiệp được bảo hành thế nào?”, hệ thống sẽ truy xuất nội dung liên quan trong tài liệu đã nạp thay vì trả lời chung chung như một chatbot công cộng.
1.2. Ollama là gì?
Ollama là công cụ giúp chạy các mô hình ngôn ngữ lớn trên máy local hoặc server riêng. Tài liệu chính thức của Ollama mô tả đây là cách đơn giản để chạy các model như Gemma, DeepSeek, Qwen và nhiều mô hình mở khác. Trong kiến trúc này, Ollama là “động cơ model”, còn AnythingLLM là lớp ứng dụng để người dùng thao tác, quản lý tài liệu và chat.
Ollama cũng cung cấp API để ứng dụng khác gọi model. Nhờ đó, AnythingLLM có thể gửi prompt, context được truy xuất từ tài liệu và nhận phản hồi từ model đang chạy trên VPS. Với doanh nghiệp, lợi ích lớn nhất là không phải mặc định gửi nội dung tài liệu sang API cloud nếu đã chọn mô hình local hoàn toàn.
Một lưu ý chuyên môn: Ollama không tự biến hệ thống thành “AI doanh nghiệp hoàn chỉnh”. Nó chỉ giải quyết phần chạy model. Muốn có quản lý workspace, upload tài liệu, phân quyền, pipeline RAG và giao diện dễ dùng cho người không chuyên, doanh nghiệp cần một lớp ứng dụng như AnythingLLM hoặc các nền tảng tương đương.
1.3. Tại sao chọn self-host?
Self-host phù hợp khi doanh nghiệp muốn kiểm soát nơi dữ liệu được lưu, nơi model xử lý prompt và cách người dùng truy cập hệ thống. Với tài liệu nhạy cảm như hợp đồng, báo giá, hồ sơ khách hàng, SOP nội bộ hoặc tài liệu đào tạo, việc tự host giúp giảm phụ thuộc vào chính sách của nền tảng bên ngoài.
- Kiểm soát dữ liệu: tài liệu, embedding và lịch sử vận hành có thể được lưu trên VPS hoặc hạ tầng riêng.
- Kiểm soát chi phí: giảm phụ thuộc vào token API cloud trong các tác vụ hỏi đáp tài liệu lặp lại.
- Kiểm soát truy cập: có thể đặt sau VPN, IP allowlist, reverse proxy và chính sách phân quyền nội bộ.
- Tùy biến workflow: mỗi phòng ban có workspace, prompt và bộ tài liệu riêng.
Dù vậy, self-host không phải lựa chọn “miễn phí và không cần vận hành”. Doanh nghiệp vẫn cần quản trị server, cập nhật phần mềm, backup, giám sát tài nguyên và xử lý lỗi. Vì vậy, cách tiếp cận hợp lý là bắt đầu bằng pilot nhỏ, đo hiệu quả thực tế rồi mới mở rộng.
2. Kiến trúc tổng thể khi tự host AnythingLLM + Ollama trên VPS

2.1. Thành phần chính
Một hệ thống tự host AnythingLLM, Ollama trên VPS thường gồm năm lớp. Lớp đầu tiên là VPS Linux, nơi chạy các dịch vụ chính. Lớp thứ hai là Docker hoặc Docker Compose để triển khai ứng dụng ổn định, dễ cập nhật và dễ tách dữ liệu bằng volume. Lớp thứ ba là Ollama, chịu trách nhiệm chạy chat model và có thể chạy cả embedding model nếu cấu hình phù hợp.
Lớp thứ tư là AnythingLLM, nơi người dùng đăng nhập, tạo workspace, upload tài liệu và đặt câu hỏi. Lớp cuối cùng là vùng lưu trữ dữ liệu: file gốc, dữ liệu đã xử lý, vector database, cấu hình workspace và log hệ thống. Đây là phần cần được backup và bảo vệ cẩn thận.
Theo kinh nghiệm triển khai, lỗi phổ biến nhất không nằm ở model, mà nằm ở networking giữa container và host. Khi AnythingLLM chạy trong Docker còn Ollama chạy trực tiếp trên VPS, địa chỉ localhost trong container không đồng nghĩa với localhost của máy chủ. Tài liệu Docker của AnythingLLM cũng nhấn mạnh vấn đề kết nối localhost/Ollama là lỗi thường gặp khi triển khai.
2.2. Luồng dữ liệu và bảo mật
Luồng xử lý RAG có thể hiểu đơn giản như sau: người quản trị upload tài liệu vào workspace, AnythingLLM tách tài liệu thành các đoạn nhỏ, tạo embedding cho từng đoạn, lưu vào vector database, sau đó khi người dùng đặt câu hỏi, hệ thống tìm các đoạn liên quan nhất và gửi chúng làm ngữ cảnh cho model Ollama trả lời.
Điểm quan trọng là model không “học lại” toàn bộ tài liệu theo nghĩa huấn luyện mới. Nó nhận các đoạn liên quan trong từng lượt hỏi và tạo câu trả lời dựa trên ngữ cảnh đó. Vì vậy, chất lượng trả lời phụ thuộc mạnh vào chất lượng tài liệu, cách chunk, embedding model, prompt hệ thống và số lượng context được đưa vào model.
Góc nhìn chuyên gia: “Một chatbot nội bộ tốt không bắt đầu từ model lớn nhất, mà bắt đầu từ dữ liệu sạch, workspace đúng phạm vi và quy trình kiểm thử có câu hỏi thật từ người dùng cuối.”
Về bảo mật, nếu doanh nghiệp cấu hình AnythingLLM chỉ gọi Ollama local và không bật các provider cloud cho dữ liệu nhạy cảm, nội dung truy vấn không cần gửi sang API AI công cộng. Nhưng vẫn cần bảo vệ VPS như một hệ thống sản xuất: HTTPS, firewall, SSH key, quyền người dùng, backup mã hóa và kiểm soát tài liệu upload.
2.3. Yêu cầu hệ thống và tài nguyên
Không có một cấu hình VPS đúng cho mọi doanh nghiệp. Pilot nhỏ cho 1-3 người có thể bắt đầu với VPS Linux, CPU đủ mạnh, RAM từ mức trung bình trở lên và SSD để lưu model/tài liệu. Với nhóm lớn hơn, nhiều truy vấn đồng thời hoặc yêu cầu phản hồi nhanh, cần cân nhắc RAM cao hơn, NVMe, GPU server hoặc tách Ollama sang máy chủ riêng.
| Quy mô | Cấu hình định hướng | Lưu ý vận hành |
|---|---|---|
| Pilot nội bộ | CPU VPS, RAM vừa phải, SSD đủ lưu model nhỏ | Phù hợp thử nghiệm RAG, tốc độ có thể chưa tối ưu |
| Team 5-20 người | CPU mạnh hơn, RAM cao, SSD/NVMe, backup định kỳ | Cần giám sát tài nguyên và tối ưu model |
| Sản xuất nghiêm túc | GPU hoặc máy chủ riêng cho model, reverse proxy, VPN/IP allowlist | Cần quy trình bảo mật, cập nhật và phân quyền rõ ràng |
Với tiếng Việt, doanh nghiệp nên benchmark bằng bộ câu hỏi thật thay vì chỉ dựa vào lời quảng cáo model. Một model nhỏ nhưng bám tài liệu tốt, phản hồi ổn định và dễ vận hành có thể phù hợp hơn một model lớn nhưng chậm, tốn tài nguyên và khó kiểm soát.
3. Chuẩn bị VPS và công cụ cần thiết

3.1. Chọn và cấu hình VPS
Trước khi cài đặt, hãy xác định mục tiêu: demo nội bộ, pilot cho một phòng ban hay hệ thống dùng thường xuyên. VPS nên chạy Linux ổn định, có quyền root hoặc sudo, đủ dung lượng lưu model và tài liệu, đồng thời có phương án backup. Nếu triển khai cho doanh nghiệp, nên dùng domain riêng như ai.tencongty.vn thay vì truy cập bằng IP thô.
Các bước nền tảng gồm cập nhật hệ điều hành, tạo user quản trị riêng, dùng SSH key, tắt đăng nhập root bằng mật khẩu nếu có thể, bật firewall và chỉ mở các port cần thiết. Giao diện AnythingLLM không nên public trần trên internet nếu chứa dữ liệu nội bộ; tối thiểu cần HTTPS và xác thực mạnh, tốt hơn là đặt sau VPN hoặc IP allowlist.
3.2. Cài Docker và Docker Compose
Docker giúp việc triển khai AnythingLLM gọn và dễ tái lập hơn. Thay vì cài nhiều phụ thuộc trực tiếp lên hệ điều hành, doanh nghiệp có thể chạy ứng dụng trong container, mount volume để giữ dữ liệu và cập nhật image khi cần. Với đội IT nhỏ, đây là cách giảm rủi ro “máy này chạy được, máy kia không chạy được”.
Khi dùng Docker Compose, nên tách rõ volume dữ liệu, biến môi trường và network. Nếu sau này cần di chuyển VPS, phần quan trọng nhất là backup volume, file cấu hình và danh sách model Ollama đang dùng. Đây là thói quen vận hành nhỏ nhưng quyết định khả năng khôi phục khi có sự cố.
3.3. Cài Ollama
Sau khi có VPS và Docker, bước tiếp theo là cài Ollama, tải model chat và chọn embedding model phù hợp. Ollama docs cung cấp hướng dẫn cài đặt cho Linux, macOS và Windows, nhưng với bài toán doanh nghiệp, Linux VPS thường là lựa chọn phổ biến hơn vì dễ triển khai dịch vụ nền, giám sát và tự động hóa.
Về thực tế, nên bắt đầu với model vừa phải để kiểm thử luồng end-to-end trước: AnythingLLM có truy cập được Ollama không, model có phản hồi không, embedding có chạy không, tài liệu có được truy xuất đúng không. Khi toàn bộ pipeline đã ổn, doanh nghiệp mới nên thử model lớn hơn hoặc tối ưu cấu hình hiệu năng.
Ở phần tiếp theo của bài viết, chúng ta sẽ đi vào cài đặt và cấu hình AnythingLLM, kết nối endpoint Ollama, tạo workspace, upload tài liệu và kiểm thử RAG bằng bộ câu hỏi thực tế cho doanh nghiệp.
4. Cài đặt và cấu hình AnythingLLM

4.1. Chạy AnythingLLM bằng Docker
Sau khi VPS đã sẵn sàng và Ollama phản hồi ổn định, bước tiếp theo là triển khai AnythingLLM. Với môi trường doanh nghiệp, Docker là lựa chọn nên ưu tiên vì giúp tách ứng dụng khỏi hệ điều hành, dễ cập nhật và dễ backup dữ liệu. Theo tài liệu Docker chính thức của AnythingLLM, nền tảng này có thể chạy bằng container và cần chú ý đến cách kết nối dịch vụ localhost từ bên trong Docker.
Về nguyên tắc vận hành, không nên chạy container mà không mount volume dữ liệu. Nếu dữ liệu ứng dụng, workspace, file đã upload và cấu hình chỉ nằm trong container tạm thời, doanh nghiệp có thể mất toàn bộ khi xóa hoặc cập nhật container. Cách làm an toàn hơn là tạo thư mục riêng trên VPS, mount vào container, sau đó đưa thư mục này vào chính sách backup định kỳ.
- Tạo thư mục dữ liệu riêng: ví dụ một thư mục dành cho AnythingLLM và một thư mục riêng cho backup.
- Chạy container có volume: đảm bảo dữ liệu không mất khi container được cập nhật.
- Đặt sau reverse proxy: dùng Nginx hoặc Caddy để cấu hình HTTPS và domain nội bộ.
- Kiểm tra log khi khởi động: phát hiện sớm lỗi quyền ghi, lỗi port hoặc lỗi network.
Trong triển khai thực tế, CentriX thường khuyến nghị doanh nghiệp ghi lại toàn bộ biến môi trường, port, volume và phiên bản image đang dùng. Tài liệu hóa các thông tin nhỏ này giúp đội IT dễ bàn giao, khôi phục và audit hệ thống về sau.
4.2. Kết nối AnythingLLM với Ollama
Khi vào giao diện thiết lập của AnythingLLM, doanh nghiệp cần chọn Ollama làm LLM provider, nhập endpoint phù hợp và chọn model chat đã tải trên VPS. Tài liệu tích hợp Ollama của AnythingLLM nêu endpoint mặc định thường là http://127.0.0.1:11434 khi chạy cục bộ, nhưng trong môi trường Docker cần hiểu đúng sự khác nhau giữa localhost của container và localhost của host.
Nếu AnythingLLM không thấy model Ollama, hãy kiểm tra theo thứ tự: Ollama service có đang chạy không, model đã được pull chưa, port 11434 có mở đúng trong phạm vi nội bộ không, container có route được tới host không, và endpoint có bị nhập sai giao thức hoặc địa chỉ IP không. Không nên mở API Ollama công khai ra internet nếu không có lớp bảo vệ phù hợp.
Với embedding, AnythingLLM cũng có thể dùng Ollama làm embedder. Tài liệu embedder Ollama của AnythingLLM khuyến nghị tải model embedding phù hợp và chọn trong phần cài đặt để tài liệu upload được xử lý qua Ollama. Đây là điểm quan trọng vì RAG không chỉ cần model trả lời, mà còn cần embedding tốt để truy xuất đúng đoạn tài liệu.
4.3. Tạo workspace và upload tài liệu
Workspace nên được thiết kế theo logic vận hành, không phải theo cảm tính. Một doanh nghiệp có thể tạo workspace “Sales”, “HR”, “CSKH”, “Sản phẩm”, “Quy trình nội bộ” thay vì đổ toàn bộ PDF, DOCX và TXT vào một nơi. Khi phạm vi dữ liệu rõ, câu trả lời thường chính xác hơn và dễ kiểm soát quyền truy cập hơn.
Trước khi upload, nên làm sạch tài liệu: bỏ bản nháp lỗi thời, đặt tên file có quy chuẩn, tách tài liệu quá dài theo chủ đề, kiểm tra file scan có OCR chưa và loại bỏ thông tin không cần thiết. Một chatbot RAG không thể trả lời tốt nếu dữ liệu đầu vào mâu thuẫn, trùng lặp hoặc đã hết hiệu lực.
Ví dụ, phòng nhân sự có thể upload sổ tay nhân viên, quy trình onboarding, chính sách nghỉ phép và mẫu biểu nội bộ. Sau đó, người quản trị kiểm thử bằng các câu hỏi như: “Nhân viên thử việc có được nghỉ phép không?”, “Quy trình xin nghỉ dài ngày gồm những bước nào?” hoặc “Chính sách làm việc từ xa áp dụng cho bộ phận nào?”.
5. Triển khai RAG và kiểm thử

5.1. Thiết lập vector database và các tham số
RAG, hay Retrieval-Augmented Generation, là kỹ thuật kết hợp truy xuất tài liệu với khả năng sinh câu trả lời của LLM. Trong mô hình tự host AnythingLLM, Ollama, vector database lưu biểu diễn ngữ nghĩa của tài liệu; khi người dùng hỏi, hệ thống tìm các đoạn liên quan nhất rồi đưa vào prompt cho model.
Doanh nghiệp nên quan tâm đến ba tham số: kích thước chunk, số lượng đoạn được truy xuất và chất lượng embedding model. Chunk quá ngắn có thể thiếu ngữ cảnh; chunk quá dài có thể làm loãng nội dung. Số đoạn truy xuất quá ít khiến câu trả lời thiếu căn cứ, còn quá nhiều có thể làm model bị nhiễu hoặc tốn tài nguyên.
Không nên đánh giá RAG bằng cảm giác “chatbot trả lời nghe hay”. Hãy yêu cầu hệ thống trả lời dựa trên tài liệu, ưu tiên nêu rõ căn cứ, và thẳng thắn nói “không tìm thấy thông tin” khi tài liệu không có đáp án. Đây là điểm khác biệt giữa chatbot nội bộ đáng tin cậy và một công cụ tạo văn bản chung chung.
5.2. Kiểm thử với bộ câu hỏi thực tế
Một bộ kiểm thử tốt nên được lấy từ tình huống thật của doanh nghiệp. Với đội sales, đó có thể là câu hỏi về bảng giá, điều kiện bảo hành, chính sách chiết khấu. Với HR, đó là nghỉ phép, onboarding, quy định làm việc. Với CSKH, đó là lỗi thường gặp, quy trình đổi trả và cách phản hồi khách hàng.
- Câu hỏi có đáp án rõ trong tài liệu: dùng để kiểm tra khả năng truy xuất đúng.
- Câu hỏi không có đáp án: dùng để kiểm tra hệ thống có bịa hay biết từ chối.
- Câu hỏi tiếng Việt tự nhiên: dùng để đánh giá khả năng hiểu ngôn ngữ của model.
- Câu hỏi có thuật ngữ ngành: dùng để kiểm tra độ bám ngữ cảnh chuyên môn.
- Câu hỏi cần tổng hợp nhiều đoạn: dùng để đánh giá năng lực kết nối thông tin.
Trong một dự án pilot, nên chấm điểm thủ công theo các tiêu chí: đúng nội dung, có căn cứ, dễ hiểu, không lộ dữ liệu ngoài phạm vi, tốc độ phản hồi chấp nhận được. Sau 20-30 câu hỏi thật, doanh nghiệp sẽ có bức tranh chính xác hơn nhiều so với việc chỉ chạy demo vài câu.
6. Bảo mật và quản trị dữ liệu

6.1. Zero data leakage hiểu đúng
“Zero data leakage” trong bối cảnh này nên được hiểu là thiết kế để dữ liệu không cần rời khỏi hạ tầng do doanh nghiệp kiểm soát khi xử lý AI. Điều này khác với cam kết rằng hệ thống không bao giờ có rủi ro. Nếu VPS bị cấu hình sai, tài khoản quản trị bị lộ, backup không mã hóa hoặc giao diện được mở public với mật khẩu yếu, dữ liệu vẫn có thể bị rò rỉ.
Ollama nhấn mạnh khả năng chạy model cục bộ và giữ dữ liệu trong phạm vi người dùng kiểm soát, nhưng trách nhiệm bảo mật hạ tầng vẫn thuộc về đơn vị triển khai. Với doanh nghiệp, đây là điểm cần nhìn nhận thực tế: self-host tăng quyền kiểm soát, đồng thời tăng trách nhiệm vận hành.
6.2. Biện pháp tăng cường bảo mật
Checklist tối thiểu cho môi trường doanh nghiệp gồm SSH key, firewall, HTTPS, backup mã hóa, phân quyền workspace và chính sách upload tài liệu. Nếu hệ thống chứa dữ liệu nhạy cảm, nên đặt AnythingLLM sau VPN, Zero Trust Access hoặc IP allowlist thay vì mở trực tiếp cho toàn internet.
- Không dùng mật khẩu mặc định, không chia sẻ tài khoản quản trị.
- Chỉ mở các port cần thiết, hạn chế truy cập SSH theo IP nếu có thể.
- Kiểm tra log định kỳ để phát hiện truy cập bất thường.
- Phân quyền workspace theo phòng ban và thu hồi quyền khi nhân sự nghỉ việc.
- Backup dữ liệu theo lịch và kiểm tra khả năng khôi phục, không chỉ backup cho có.
Ngoài kỹ thuật, doanh nghiệp cần chính sách dữ liệu: tài liệu nào được upload, ai chịu trách nhiệm cập nhật, nội dung nhạy cảm có cần ẩn trước khi đưa vào hệ thống hay không, và dữ liệu cũ được xóa theo chu kỳ nào.
7. So sánh giải pháp với ChatGPT/cloud AI

7.1. Khi nào nên dùng self-host AnythingLLM + Ollama?
Self-host phù hợp khi doanh nghiệp ưu tiên kiểm soát dữ liệu, muốn hỏi đáp trên kho tài liệu nội bộ và có đội kỹ thuật đủ khả năng vận hành VPS. Các use case điển hình gồm trợ lý tri thức nội bộ, chatbot tài liệu sản phẩm, helpdesk IT, hỗ trợ sales và đào tạo nhân sự.
| Tiêu chí | Self-host AnythingLLM + Ollama | ChatGPT/cloud AI |
|---|---|---|
| Kiểm soát dữ liệu | Cao hơn nếu cấu hình nội bộ đúng | Phụ thuộc chính sách nền tảng |
| Chất lượng model | Phụ thuộc model local và tài nguyên VPS | Thường mạnh và cập nhật nhanh |
| Vận hành | Cần IT quản trị server, backup, bảo mật | Dễ dùng hơn, ít quản trị hạ tầng |
| RAG tài liệu riêng | Tùy biến sâu theo workspace | Có thể tiện lợi nhưng phụ thuộc nền tảng |
7.2. Khi cần dùng ChatGPT hoặc cloud AI?
Không phải mọi tác vụ đều cần self-host. Với brainstorming, viết nội dung sáng tạo, nghiên cứu thông tin công khai, phân tích ý tưởng hoặc cần model frontier mạnh, ChatGPT, Claude, Gemini, Perplexity hoặc Copilot vẫn có giá trị lớn. Mô hình hợp lý với nhiều doanh nghiệp là hybrid: dữ liệu nhạy cảm xử lý trong hệ thống nội bộ, còn tác vụ sáng tạo hoặc nghiên cứu rộng dùng công cụ cloud phù hợp.
Đây cũng là hướng CentriX.digital thường tư vấn: không thần thánh hóa một công cụ duy nhất, mà thiết kế hệ sinh thái AI theo nhu cầu thật của đội nhóm. Một doanh nghiệp có thể vừa dùng tài khoản AI bản quyền cho productivity, vừa có AnythingLLM và Ollama trên VPS để quản trị tri thức riêng.
8. Lỗi thường gặp và xử lý
8.1. Kết nối lỗi giữa AnythingLLM và Ollama
Lỗi phổ biến nhất là nhập endpoint sai do nhầm localhost. Nếu AnythingLLM chạy trong Docker, 127.0.0.1 có thể trỏ về chính container, không phải VPS host nơi Ollama đang chạy. Hãy kiểm tra network mode, host gateway, firewall và trạng thái Ollama service. Ngoài ra, cần chắc chắn model đã được tải và Ollama có quyền truy cập tài nguyên cần thiết.
8.2. Chatbot trả lời không liên quan tài liệu
Nếu câu trả lời không bám tài liệu, nguyên nhân thường đến từ file đầu vào kém chất lượng, OCR lỗi, chunking chưa phù hợp, embedding model không tốt với tiếng Việt hoặc workspace chứa quá nhiều tài liệu không cùng chủ đề. Cách xử lý là làm sạch dữ liệu, tách workspace, giảm tài liệu lỗi thời và kiểm thử lại bằng bộ câu hỏi chuẩn.
Cũng nên tinh chỉnh prompt hệ thống để yêu cầu chatbot trả lời dựa trên tài liệu, không bịa thông tin khi không có căn cứ. Với doanh nghiệp, một câu trả lời “không tìm thấy trong tài liệu hiện có” thường đáng tin hơn một câu trả lời dài nhưng không kiểm chứng được.
9. FAQ tự host AnythingLLM + Ollama
9.1. AnythingLLM hỗ trợ tiếng Việt không?
Có thể dùng tiếng Việt, nhưng chất lượng phụ thuộc model, embedding và tài liệu đầu vào. Doanh nghiệp nên benchmark bằng câu hỏi tiếng Việt thực tế, bao gồm cả từ viết tắt, thuật ngữ ngành và cách hỏi tự nhiên của nhân viên.
9.2. VPS có cần GPU không?
Không bắt buộc cho pilot nhỏ, nhưng GPU giúp cải thiện tốc độ và trải nghiệm khi dùng model lớn hoặc nhiều người truy cập đồng thời. Với hệ thống sản xuất, nên đánh giá latency, số người dùng, kích thước model và ngân sách trước khi quyết định dùng CPU VPS, GPU VPS hay máy chủ riêng.
9.3. Có nên đưa toàn bộ tài liệu công ty vào một workspace?
Không nên. Workspace càng rộng, khả năng nhiễu ngữ cảnh càng cao. Nên chia theo phòng ban, mục đích hoặc cấp độ bảo mật để dễ quản trị quyền truy cập và tăng độ chính xác khi truy xuất.
9.4. Self-host có thay thế hoàn toàn ChatGPT không?
Không nhất thiết. Self-host mạnh ở dữ liệu riêng và kiểm soát hạ tầng; ChatGPT hoặc các nền tảng cloud AI vẫn phù hợp cho sáng tạo, nghiên cứu và tác vụ cần model rất mạnh. Doanh nghiệp nên chọn mô hình theo rủi ro dữ liệu và mục tiêu công việc.
10. Kết luận và bước tiếp theo
Tự host AnythingLLM và Ollama trên VPS là một hướng đi thực tế cho doanh nghiệp muốn xây dựng ChatGPT riêng, khai thác tài liệu nội bộ và giảm rủi ro đưa dữ liệu nhạy cảm lên nền tảng AI công cộng. Giá trị lớn nhất không chỉ nằm ở việc “cài được chatbot”, mà ở khả năng biến tri thức rời rạc trong doanh nghiệp thành một hệ thống có thể tra cứu, kiểm thử, phân quyền và cải tiến liên tục.
Tuy nhiên, để triển khai hiệu quả, doanh nghiệp cần nhìn đủ ba lớp: công cụ AI, hạ tầng kỹ thuật và quy trình dữ liệu. AnythingLLM và Ollama giải quyết phần nền tảng, nhưng chất lượng vận hành phụ thuộc vào cách chọn model, tổ chức workspace, làm sạch tài liệu, bảo mật VPS và đào tạo người dùng cuối.
Nếu doanh nghiệp của bạn đang cân nhắc xây dựng AI nội bộ nhưng chưa rõ nên bắt đầu từ VPS, model, tài khoản AI hay workflow phòng ban, CentriX.digital có thể đồng hành từ tư vấn công cụ, phần mềm bản quyền đến giải pháp hạ tầng số. Mục tiêu không chỉ là có thêm một chatbot, mà là rút ngắn khoảng cách giữa ý tưởng AI và một hệ thống thực sự tạo giá trị cho đội ngũ.



