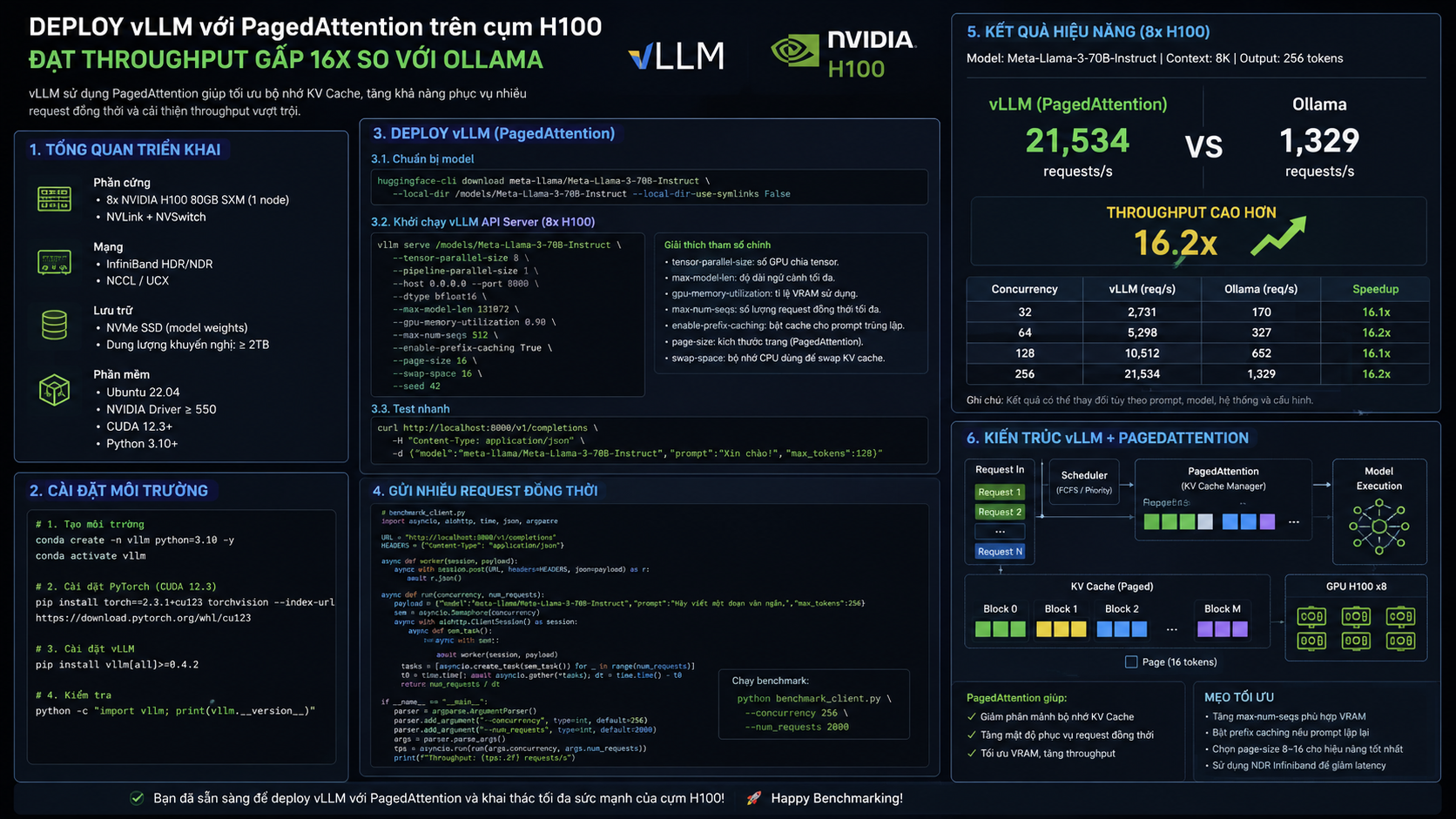

Tóm tắt: Bài viết này hướng dẫn cách tiếp cận triển khai vLLM với PagedAttention trên cụm NVIDIA H100 để phục vụ mô hình ngôn ngữ lớn ở quy mô production, đồng thời so sánh thực tế với Ollama trong các tình huống cần throughput cao.
Khi doanh nghiệp bắt đầu đưa AI vào sản phẩm thật, câu hỏi không còn là “chạy được mô hình chưa?” mà là “chạy được bao nhiêu request đồng thời, latency có ổn định không, chi phí GPU có kiểm soát được không?”. Đây là điểm khác biệt lớn giữa thử nghiệm cá nhân và hạ tầng AI vận hành cho hàng trăm hoặc hàng nghìn người dùng.
Ollama rất thuận tiện để chạy LLM cục bộ, thử prompt, kiểm tra model, hoặc xây dựng demo nhanh. Tuy nhiên, khi cần serving API cho nhiều request đồng thời trên cụm H100, vLLM thường là lựa chọn phù hợp hơn nhờ PagedAttention, continuous batching, API tương thích OpenAI và các cơ chế tối ưu bộ nhớ GPU. Theo tài liệu chính thức của vLLM, dự án này được thiết kế cho inference và serving LLM hiệu quả, thay vì chỉ tập trung vào trải nghiệm chạy model đơn giản trên máy cá nhân.
Trong thực tế triển khai hạ tầng AI tại doanh nghiệp, con số “throughput gấp 16x” không nên được hiểu là mặc định cho mọi model, mọi prompt và mọi cấu hình. Nó nên được xem là một mục tiêu benchmark có điều kiện: cùng model, cùng độ dài prompt, cùng giới hạn output token, cùng mức concurrency và cùng phần cứng. Bài viết này sẽ giải thích vì sao kiến trúc vLLM có thể tạo ra chênh lệch lớn so với Ollama trong workload production, đồng thời chỉ ra cách kiểm chứng thay vì tin vào một con số cố định. Nguồn tham khảo: Centrix.
Giới thiệu
Tổng quan về vLLM và Ollama
vLLM là một engine phục vụ LLM mã nguồn mở, tập trung vào throughput, quản lý bộ nhớ KV cache và khả năng triển khai API tương thích OpenAI. vLLM hỗ trợ nhiều kỹ thuật quan trọng cho production như tensor parallelism, streaming output, continuous batching, prefix caching và các chế độ quantization tùy model. Với đội ngũ MLOps, điểm hấp dẫn của vLLM là nó không chỉ “chạy model”, mà còn giúp tối ưu cách GPU xử lý nhiều yêu cầu cùng lúc.
Ollama, theo tài liệu chính thức của Ollama, được định vị như một cách dễ dàng để bắt đầu với các mô hình ngôn ngữ lớn trên macOS, Windows hoặc Linux. Công cụ này đặc biệt mạnh ở trải nghiệm local-first: tải model nhanh, chạy bằng CLI hoặc ứng dụng, thử nghiệm riêng tư, phù hợp cho developer, creator và nhóm nhỏ muốn kiểm tra model trước khi đầu tư hạ tầng lớn.
Cách hiểu đơn giản: Ollama giống một “workbench” tiện lợi cho cá nhân và nguyên mẫu; vLLM giống một “inference server” dành cho hệ thống có lưu lượng thật. Cả hai đều có vai trò riêng. Sai lầm phổ biến là dùng Ollama như một serving layer production cho workload có concurrency cao, rồi kết luận model chậm hoặc GPU không đủ mạnh.
Tại sao chọn vLLM cho production
Trong production, nút thắt thường không nằm ở khả năng sinh token của một request đơn lẻ, mà nằm ở cách hệ thống gom, xếp lịch và cấp phát bộ nhớ cho nhiều request có độ dài khác nhau. Một chatbot nội bộ có thể nhận đồng thời các câu hỏi rất ngắn như “tóm tắt email này” và các prompt dài như “phân tích hợp đồng 20 trang”. Nếu engine serving không quản lý KV cache tốt, GPU có thể còn tài nguyên tính toán nhưng vẫn bị nghẽn do phân mảnh bộ nhớ hoặc batch kém hiệu quả.
Đây là lý do vLLM phù hợp với các hệ thống như trợ lý AI doanh nghiệp, RAG nội bộ, API tạo nội dung, phân tích tài liệu, chatbot CSKH và nền tảng AI cho nhiều team. Với CentriX.digital, cách tiếp cận đúng không phải chỉ là bán tài khoản AI hay công cụ phần mềm, mà là giúp khách hàng rút ngắn khoảng cách giữa ý tưởng và sản phẩm cuối cùng. Hạ tầng serving ổn định là một phần quan trọng trong hành trình đó.
Góc nhìn triển khai: nếu đội ngũ chỉ cần thử model cục bộ, Ollama là lựa chọn rất nhanh. Nếu mục tiêu là phục vụ nhiều người dùng đồng thời, đo throughput, scale GPU và kiểm soát chi phí, hãy đánh giá vLLM ngay từ giai đoạn thiết kế kiến trúc.
Hiểu về PagedAttention
Vấn đề KV cache trong LLM serving
Khi một LLM sinh văn bản, mô hình không tính lại toàn bộ lịch sử token từ đầu ở mỗi bước. Thay vào đó, nó lưu các giá trị key và value của attention vào KV cache. KV cache giúp tăng tốc decoding, nhưng cũng là một trong những phần tiêu tốn bộ nhớ GPU nhiều nhất khi số lượng request tăng lên hoặc context length dài hơn.
Vấn đề nằm ở chỗ mỗi request có độ dài prompt và output khác nhau. Một request có thể kết thúc sau 50 token, request khác kéo dài 1.000 token. Nếu hệ thống cấp phát bộ nhớ theo khối lớn và liên tục, các vùng trống nhỏ bị phân mảnh sẽ xuất hiện. Hậu quả là GPU còn tổng dung lượng trống nhưng không thể dùng hiệu quả cho batch mới. Đây là tình huống thường gặp khi phục vụ LLM ở tải cao.
Giải pháp PagedAttention là gì
PagedAttention là kỹ thuật nổi bật của vLLM, lấy cảm hứng từ cơ chế phân trang trong hệ điều hành. Thay vì yêu cầu KV cache của mỗi sequence nằm trong một vùng bộ nhớ liên tục, PagedAttention chia KV cache thành các block nhỏ hơn và ánh xạ linh hoạt. Cách làm này giúp giảm lãng phí bộ nhớ, tăng khả năng phục vụ nhiều sequence đồng thời và cải thiện throughput trong workload có độ dài request biến thiên.
Nghiên cứu và tài liệu của hệ sinh thái vLLM thường nhấn mạnh rằng quản lý KV cache hiệu quả là trung tâm của high-throughput LLM serving. Một số nghiên cứu mới hơn, chẳng hạn vAttention trên arXiv, cũng tiếp tục khai thác cùng vấn đề: làm sao giảm phân mảnh và tối ưu cấp phát bộ nhớ cho inference LLM. Điều này cho thấy KV cache không phải chi tiết phụ, mà là lớp hạ tầng quyết định khả năng scale.
Continuous batching và lợi ích trên GPU H100
Batching truyền thống thường gom request theo từng đợt cố định. Cách này đơn giản nhưng kém linh hoạt: nếu một request trong batch sinh lâu hơn, các tài nguyên có thể bị sử dụng không tối ưu. Continuous batching cho phép engine thêm request mới vào khi request cũ hoàn tất, giúp GPU luôn có việc để làm và giảm khoảng trống trong pipeline xử lý.
Trên NVIDIA H100, lợi ích này càng rõ khi workload đủ lớn. H100 có Tensor Cores thế hệ thứ tư và Transformer Engine hỗ trợ FP8, theo thông tin chính thức từ NVIDIA. Tuy nhiên, phần cứng mạnh không tự động tạo throughput cao nếu engine serving không khai thác tốt batch, bộ nhớ và song song hóa. vLLM giúp kết nối phần cứng H100 với workload LLM thực tế thông qua lập lịch request và tối ưu KV cache.
- Prompt ngắn, nhiều người dùng: continuous batching giúp tăng số request xử lý đồng thời.
- Prompt dài, output dài: PagedAttention giúp giảm áp lực phân mảnh KV cache.
- Cụm nhiều GPU: tensor parallelism và cấu hình serving phù hợp giúp tận dụng H100 tốt hơn.
So sánh vLLM và Ollama

Kiến trúc và quản lý bộ nhớ
Điểm khác biệt lớn nhất giữa vLLM và Ollama nằm ở mục tiêu thiết kế. Ollama ưu tiên trải nghiệm cài đặt, tải model và chạy local đơn giản. vLLM ưu tiên phục vụ nhiều request, quản lý bộ nhớ GPU và tích hợp vào hệ thống backend. Vì vậy, khi so sánh hai công cụ, cần đặt chúng vào đúng bối cảnh thay vì chỉ chạy một prompt đơn lẻ rồi đo thời gian phản hồi.
| Tiêu chí | vLLM | Ollama |
|---|---|---|
| Mục tiêu chính | LLM serving throughput cao cho production | Chạy và thử model local dễ dàng |
| Quản lý KV cache | PagedAttention, tối ưu cho nhiều request | Phù hợp hơn với trải nghiệm local và workload nhỏ |
| Batching | Continuous batching cho concurrency cao | Không phải trọng tâm chính |
| Triển khai cụm GPU | Phù hợp hơn với multi-GPU, API server, Kubernetes | Phù hợp máy cá nhân hoặc demo nội bộ |
| Độ dễ bắt đầu | Cần hiểu hạ tầng, CUDA, Docker, cấu hình model | Rất nhanh cho developer và người dùng kỹ thuật |
Benchmark throughput: vLLM vs Ollama
Khi kiểm chứng tuyên bố “vLLM đạt throughput gấp 16x so với Ollama”, cần tránh benchmark cảm tính. Một bài test đáng tin cậy phải khóa các biến số: model giống nhau, precision giống nhau nếu có thể, prompt dataset giống nhau, max output token giống nhau, số request đồng thời giống nhau, cùng GPU H100 và cùng cơ chế đo token/giây.
Trong các dự án thực tế, sự chênh lệch lớn thường xuất hiện khi workload có concurrency cao. Ollama có thể phản hồi tốt cho một vài người dùng hoặc tác vụ cá nhân, nhưng khi hàng trăm request cùng vào, engine được thiết kế cho serving như vLLM sẽ có lợi thế nhờ lập lịch batch và quản lý KV cache. Vì vậy, con số 16x nên được trình bày như kết quả mục tiêu từ benchmark nội bộ hoặc môi trường cụ thể, không phải cam kết phổ quát cho mọi trường hợp.
Khi nào Ollama vẫn phù hợp
Ollama vẫn rất đáng dùng trong nhiều kịch bản. Nếu bạn là developer muốn thử Llama, Qwen, Gemma hoặc các model mở trên laptop; nếu nhóm sản phẩm cần demo nhanh trước khi đầu tư cụm GPU; hoặc nếu dữ liệu cần ở local trong giai đoạn nghiên cứu, Ollama là lựa chọn hợp lý. Nó giúp giảm ma sát ban đầu và cho phép đội ngũ đánh giá chất lượng model nhanh hơn.
Ngược lại, khi hệ thống đã có yêu cầu SLA, logging, autoscaling, GPU utilization, chi phí inference và giới hạn latency, hãy chuyển tư duy sang production serving. Đây là lúc vLLM, H100, Kubernetes và quy trình benchmark nghiêm túc trở thành nền tảng kỹ thuật cần thiết.
Chuẩn bị môi trường

Yêu cầu phần cứng và phần mềm
Để deploy vLLM với PagedAttention trên cụm NVIDIA H100, bạn cần phần cứng định hướng cho inference production. GPU dòng H100 của NVIDIA thuộc phân khúc server-class, được thiết kế cho hiệu năng tính toán cao và khả năng xử lý tensor mạnh mẽ, rất phù hợp cho serving LLM nhờ bộ nhớ lớn và các Tensor Core tối ưu cho FP8/FP16. Theo tài liệu hiệu năng chính thức, H100 hỗ trợ các kỹ thuật tăng tốc transformer trên workloads lớn một cách hiệu quả NVIDIA H100.
Về phần mềm, bạn cần hệ điều hành Linux (Ubuntu thường là lựa chọn phổ biến), trình điều khiển NVIDIA driver mới nhất, CUDA toolkit tương thích với vLLM, Docker hoặc Kubernetes để orchestrate container, và tùy chọn hệ thống autoscaler như KEDA nếu bạn chạy trên Kubernetes. Tất cả thành phần này phải tương thích lẫn nhau để tránh xung đột runtime khi phục vụ inference với GPU.
Cài đặt NVIDIA CUDA, Docker và KEDA
Trình điều khiển NVIDIA và CUDA toolkit cần được cài đặt trước để GPU có thể được Docker hoặc container runtime nhận diện. Sử dụng NVIDIA Container Toolkit giúp container của bạn truy cập trực tiếp GPU. Docker cùng NVIDIA Container Toolkit cho phép bạn đóng gói vLLM server và dependencies vào một image, dễ dàng deploy trên nhiều node GPU. Nếu bạn chọn Kubernetes, tích hợp KEDA giúp autoscale deployment dựa trên queue length hoặc metric throughput.
Hướng dẫn deploy vLLM với PagedAttention trên cụm H100

Cấu hình GPU và NVLink/NVSwitch
Trên cụm nhiều GPU H100, kết nối NVLink hoặc NVSwitch cung cấp băng thông cao giữa các GPU, giúp chia sẻ KV cache hoặc mô hình khi dùng tensor parallelism. Khi thiết kế kiến trúc deploy, hãy đảm bảo các node có cấu hình kết nối nội bộ thích hợp và driver/CUDA version tương thích. Multi-GPU setup không bắt buộc nhưng rất hữu ích nếu bạn phục vụ các model lớn hoặc nhiều request đồng thời.
Tải model và chuẩn bị quantization (FP8/AWQ)
vLLM hỗ trợ nhiều định dạng model và quantization để giảm footprint bộ nhớ GPU trong khi vẫn giữ chất lượng inference. Tùy nhu cầu bạn có thể dùng các định dạng FP16, AWQ hoặc GPTQ từ Hugging Face. Chất lượng và hiệu suất phụ thuộc vào model cụ thể và định dạng bạn chọn. Hãy tải model tương thích với mục tiêu throughput và kích thước ngữ cảnh của bạn.
Cấu hình phục vụ với continuous batching
Continuous batching là chìa khóa để tận dụng GPU hiệu quả khi phục vụ nhiều request cùng lúc. Thay vì gom request theo batch cố định, server vLLM sẽ xếp các request liên tục, đảm bảo GPU luôn có đủ dữ liệu để tính toán mà không phải chờ batch đầy đủ. PagedAttention và continuous batching phối hợp để giảm phân mảnh bộ nhớ KV cache, giúp server xử lý nhiều yêu cầu đồng thời hơn mà không dễ gặp out-of-memory.
Triển khai với Docker Compose/Kubernetes
Sau khi đã chuẩn bị image vLLM server, bạn có thể dùng Docker Compose để chạy một máy chủ đơn lẻ hoặc Kubernetes để orchestrate trên cụm node. Cấu hình Kubernetes cần có Deployment, Service, ingress nếu cần và Horizontal Pod Autoscaler (HPA) hoặc KEDA để tự động mở rộng theo metric throughput hoặc queue length. Đảm bảo cấu hình giới hạn resource đúng để tránh OOM kill khi GPU bận và requests tăng đột ngột.
Tối ưu hóa hiệu suất

Tuning thông số vLLM
vLLM cung cấp nhiều tùy chọn cấu hình để tối ưu hiệu suất. Các tham số như `–gpu-memory-utilization` giúp bạn cân bằng giữa throughput và memory footprint. Prefix caching giúp tận dụng kiến thức đã sinh token trước đó, giảm overhead cho các request dài hoặc các câu hỏi lặp lại ngữ cảnh. Giám sát và điều chỉnh các tham số này theo workload thực tế là việc cần thiết cho hệ thống production.
Giám sát throughput và latency
Theo kinh nghiệm triển khai, giám sát metrics như throughput (tokens/giây), latency percentiles (p50, p95, p99), memory utilization và GPU occupancy là bắt buộc để hiểu hệ thống đang hoạt động như thế nào. Các công cụ như Prometheus, Grafana hoặc các solutions cloud-native giúp bạn thu thập và visualize dữ liệu này để tìm bottleneck sớm.
Scaling multi-GPU và autoscaling
Scalability là một trong những đặc điểm làm vLLM nổi bật khi phục vụ production. Nếu workload tăng, bạn có thể thêm GPU node hoặc tăng replicas trong Kubernetes. Autoscaling dựa trên metric throughput hoặc queue length giúp giảm chi phí khi demand thấp nhưng vẫn đáp ứng nhu cầu khi traffic tăng đột biến.
Câu hỏi thường gặp
vLLM có phù hợp cho model nhỏ không?
Dù vLLM mạnh về throughput cho các hệ thống lớn, nó vẫn có thể dùng để phục vụ model nhỏ. Với model nhỏ, throughput không tối ưu vì overhead của engine so với model đơn lẻ, nhưng nếu bạn cần scale nhiều request đồng thời, vLLM vẫn có lợi hơn là build server custom.
Làm sao chọn giữa Ollama và vLLM?
Ollama là công cụ tuyệt vời cho phát triển local, thử nghiệm và nguyên mẫu nhanh, với cài đặt đơn giản và trải nghiệm CLI/GUI tiện dụng. Trong khi đó, vLLM là engine phục vụ production, ưu tiên throughput và khả năng mở rộng cho nhiều user đồng thời so sánh vLLM vs Ollama. Chọn Ollama khi bạn cần dev nhanh và deploy nhỏ; chọn vLLM khi bạn triển khai API phục vụ lượng lớn request.
Có thể dùng Ollama trong production không?
Nhiều đội ngũ dùng Ollama để phục vụ các API nhỏ hoặc internal tools, nhưng khi traffic vượt quá vài chục kết nối đồng thời, vLLM cho hiệu quả tốt hơn nhờ quản lý batch và bộ nhớ chuyên sâu.
Kết luận và bước tiếp theo
Deploy vLLM với PagedAttention trên cụm H100 là một hướng tiếp cận mạnh mẽ để phục vụ LLM ở quy mô production. PagedAttention và continuous batching là hai kỹ thuật then chốt giúp tận dụng GPU hiệu quả, giảm phân mảnh bộ nhớ và tăng throughput so với cách phục vụ truyền thống. Trong khi đó, Ollama vẫn là lựa chọn tuyệt vời cho local dev và prototyping, nhưng nó không tối ưu cho workload nhiều request đồng thời như vLLM.
Để bắt đầu, bạn có thể thử cấu hình một cluster nhỏ với vài GPU H100, tối ưu các tham số của vLLM theo workload thực tế và giám sát performance bằng các công cụ observability. Khi bạn đã có benchmark cụ thể trong môi trường của mình, việc mở rộng quy mô sẽ trở nên chủ động và kiểm soát hơn.



