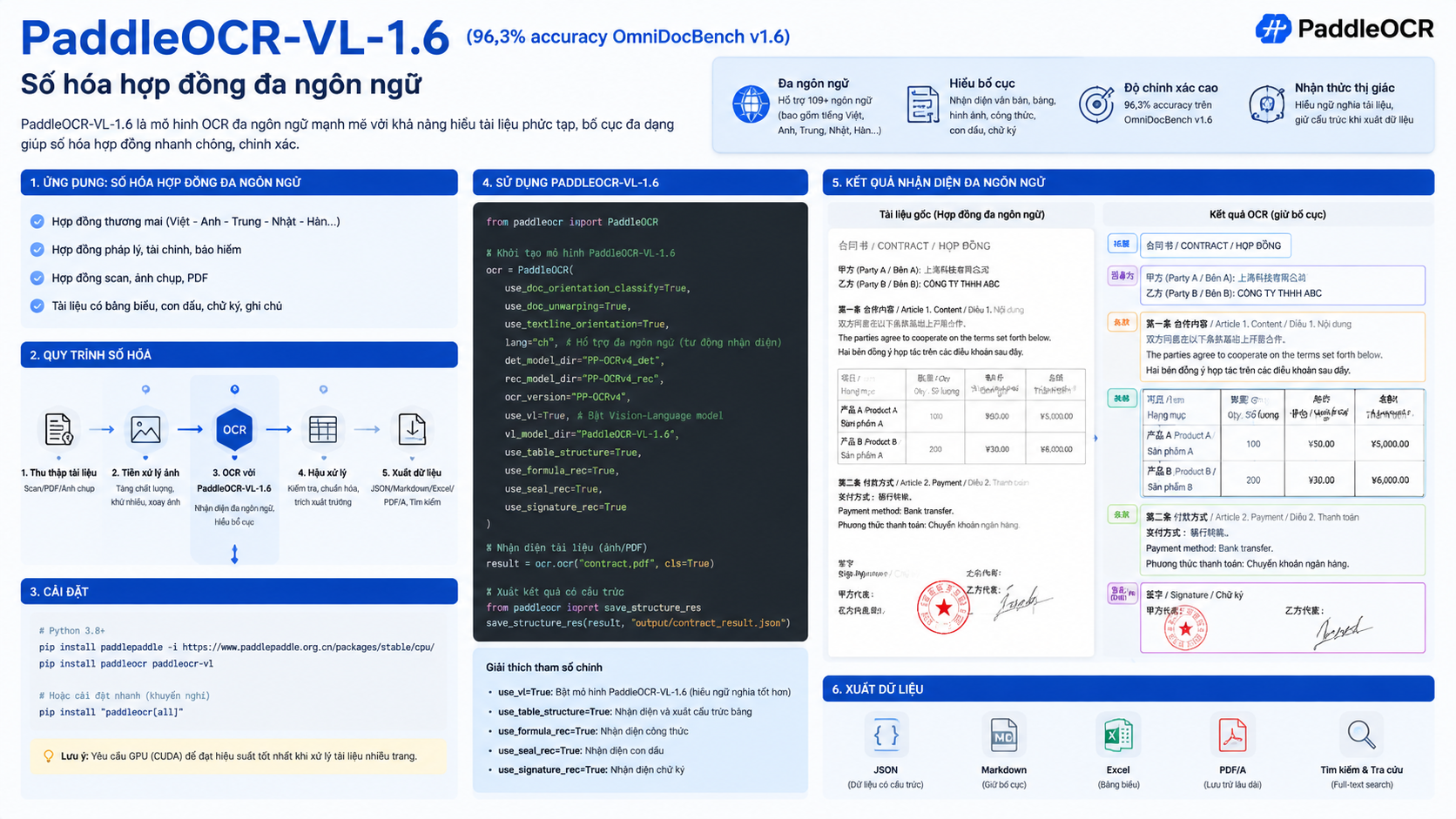

Trong bối cảnh chuyển đổi số mạnh mẽ, doanh nghiệp đối mặt với một thách thức lớn là xử lý lượng lớn hợp đồng giấy, scan và tài liệu đa ngôn ngữ một cách nhanh chóng, chính xác và có thể truy vấn tự động. PaddleOCR-VL-1.6 nổi lên như một công cụ OCR tiên tiến với khả năng trích xuất văn bản và bố cục tài liệu phức tạp. Đây không chỉ là mô hình nhận diện ký tự thông thường, mà còn hiểu cấu trúc tài liệu để chuyển các hợp đồng scan thành dữ liệu có cấu trúc phục vụ lưu trữ, tìm kiếm và phân tích sâu.
1. Chủ đề cốt lõi và từ khóa liên quan
Mục tiêu của bài viết này là hướng dẫn chi tiết cách ứng dụng PaddleOCR-VL-1.6 vào quy trình số hóa hợp đồng đa ngôn ngữ. Điều này bao gồm cách chuẩn bị dữ liệu, chạy mô hình OCR, trích xuất thông tin quan trọng như thông tin các bên, ngày ký, giá trị hợp đồng và cách lưu trữ kết quả để tích hợp vào hệ thống quản trị nội bộ.
Từ khóa chính là PaddleOCR-VL-1.6 và các nhóm từ khóa phụ như OCR hợp đồng, số hóa hợp đồng đa ngôn ngữ, trích xuất dữ liệu hợp đồng, document parsing sẽ được triển khai tự nhiên xuyên suốt bài. Nguồn tham khảo: Centrix.
2. Search intent, đối tượng và mục tiêu bài viết

Ở phần này, chúng ta hiểu rằng độc giả không chỉ muốn biết PaddleOCR-VL-1.6 là gì, mà còn cần một quy trình thực tế để áp dụng vào từng bước trong doanh nghiệp. Độc giả mục tiêu bao gồm: bộ phận pháp chế cần tra cứu điều khoản nhanh; bộ phận hành chính nhân sự muốn lưu trữ hợp đồng lao động; kế toán xử lý hợp đồng mua bán; đội chuyển đổi số xây dựng kho dữ liệu hợp đồng; cũng như nhà phát triển muốn tích hợp OCR vào hệ thống backend.
Mục tiêu bài viết là giúp bạn lập quy trình từ chuẩn bị dữ liệu đến kiểm thử và lưu trữ, đồng thời gợi ý những công cụ AI bổ trợ như ChatGPT, Claude, hoặc Gemini trong hệ sinh thái CentriX.digital để tăng hiệu quả hoạt động.
3. Vì sao PaddleOCR-VL-1.6 đáng chú ý trong số hóa hợp đồng đa ngôn ngữ?

PaddleOCR-VL-1.6 là một mô hình OCR cải tiến thuộc họ vision-language model, được thiết kế để hiểu cả ký tự lẫn cấu trúc tài liệu. Điều này đặc biệt hữu ích khi xử lý hợp đồng vì các văn bản loại này thường chứa nhiều bảng, điều khoản dài, con dấu, chữ ký và đôi khi là nhiều ngôn ngữ trong cùng một tài liệu.
Một benchmark nổi bật là kết quả trên OmniDocBench v1.6, một tập dữ liệu chuẩn để đánh giá năng lực phân tích và trích xuất thông tin từ tài liệu tổng quát. Kết quả này cho thấy mô hình có thể đạt mức độ chính xác cao trong điều kiện kiểm thử tiêu chuẩn, nhưng trong thực tế, chất lượng tài liệu đầu vào như scan mờ, font chữ phức tạp hay watermark vẫn là những yếu tố ảnh hưởng đến hiệu suất.
Về mặt kiến trúc, PaddleOCR-VL-1.6 kế thừa các ưu điểm của dòng vision-language model: tích hợp thông tin ngôn ngữ và hình ảnh để đánh giá ngữ cảnh, nhận biết layout và tách bảng biểu một cách hiệu quả. Điều này giúp phân tích hợp đồng đa ngôn ngữ như song ngữ Việt – Anh, Việt – Trung, hoặc tài liệu thương mại quốc tế trở nên dễ dàng hơn so với OCR truyền thống chỉ dựa vào nhận diện ký tự đơn thuần.
Một điểm mạnh nữa là khả năng xuất đầu ra có cấu trúc như Markdown hoặc JSON. Điều này có ý nghĩa thực tiễn lớn: dữ liệu sau OCR không chỉ là văn bản thô mà còn được phân vùng theo các trường cần thiết để dễ dàng lưu trữ trong database, tìm kiếm theo điều khoản, hoặc đưa vào quy trình pháp lý và xử lý tự động tiếp theo bằng các công cụ AI khác.
4. Khi nào nên dùng PaddleOCR-VL-1.6 cho hợp đồng?

Mô hình này phù hợp nhất với các trường hợp hợp đồng có chất lượng scan ổn, nhiều trang, bảng biểu phức tạp, chữ ký và con dấu rõ ràng. Với dạng hợp đồng song ngữ hoặc hợp đồng kỹ thuật, khả năng hiểu bố cục và trích xuất đa ngôn ngữ của PaddleOCR-VL-1.6 giúp tiết kiệm thời gian so với phương pháp thủ công.
Ngược lại, nếu tài liệu chứa nhiều chữ viết tay, scan rất mờ, hoặc dữ liệu cực kỳ nhạy cảm yêu cầu bảo mật cao, bạn cần cân nhắc kỹ và kết hợp bước kiểm duyệt của con người (human-in-the-loop) để đảm bảo chất lượng và tuân thủ các quy định về dữ liệu nhạy cảm.
So sánh nhanh với OCR truyền thống cho thấy rằng các mô hình OCR đơn thuần thường chỉ nhận ký tự chính xác mà không hiểu bố cục. Trong khi đó, PaddleOCR-VL-1.6 không chỉ đọc ký tự mà còn xác định vị trí và mối quan hệ giữa các phần của tài liệu, rất cần thiết khi phân tích hợp đồng có cấu trúc phức tạp.
5. Chuẩn bị dữ liệu hợp đồng trước khi chạy OCR

Trước khi áp dụng PaddleOCR-VL-1.6, cần chuẩn hóa dữ liệu đầu vào. Các file nên ở định dạng scan PDF hoặc ảnh JPG/PNG chất lượng cao, đặt tên file rõ ràng bao gồm mã hợp đồng, ngày và đối tác. Bạn nên tránh các hình ảnh chụp nghiêng, thiếu sáng hoặc bị cắt mép vì những yếu tố này sẽ làm giảm hiệu suất OCR.
Phân loại hợp đồng theo nhóm như mua bán, lao động, dịch vụ hay thuê văn phòng sẽ giúp bạn xây dựng schema dữ liệu trích xuất phù hợp cho từng loại. Đồng thời, xác định trước các trường thông tin cần trích xuất như số hợp đồng, ngày ký, các bên liên quan, giá trị hợp đồng và điều khoản quan trọng giúp tối ưu hóa quy trình sau này.
Cuối cùng, áp dụng các quy tắc bảo mật trước xử lý như ẩn thông tin nhạy cảm nếu dùng môi trường thử nghiệm bên ngoài và phân quyền truy cập thư mục giúp bảo vệ dữ liệu hợp đồng quan trọng.
6. Quy trình dùng PaddleOCR-VL-1.6 để số hóa hợp đồng đa ngôn ngữ

Ở giai đoạn triển khai, doanh nghiệp không nên xem OCR là một thao tác đơn lẻ. Với hợp đồng, quy trình đúng phải đi từ kiểm tra chất lượng tài liệu, nhận diện bố cục, trích xuất nội dung, chuẩn hóa dữ liệu, kiểm duyệt và cuối cùng là lưu trữ có kiểm soát. Theo tài liệu PaddleX về PaddleOCR-VL, mô hình có thể được dùng qua CLI để kiểm thử nhanh hoặc Python API để tích hợp linh hoạt vào hệ thống hiện có.
Bước 1: Nạp tài liệu và kiểm tra chất lượng trang
Trước khi xử lý bằng PaddleOCR-VL-1.6, hãy kiểm tra các yếu tố cơ bản: trang có bị thiếu không, có bị xoay 90 độ không, ảnh có mờ hoặc lóa sáng không, phần con dấu có che mất văn bản không. Trong thực tế, nhiều lỗi OCR không đến từ mô hình mà đến từ đầu vào: file scan bị nén quá mạnh, hợp đồng photocopy nhiều lần hoặc ảnh chụp từ điện thoại không đủ sáng.
Bước 2: Chạy nhận diện bố cục tài liệu
Layout parsing là bước quan trọng với hợp đồng đa ngôn ngữ. Mục tiêu không chỉ là đọc chữ, mà còn xác định đâu là tiêu đề điều khoản, đâu là bảng phụ lục, đâu là chữ ký, con dấu, header, footer và số trang. Với hợp đồng có bảng phí hoặc phụ lục kỹ thuật, việc giữ đúng cấu trúc bảng quyết định khả năng đối chiếu dữ liệu sau này.
Bước 3: Trích xuất nội dung đa ngôn ngữ
Với hợp đồng Việt – Anh, Việt – Trung hoặc Việt – Nhật, nên giữ nguyên ngôn ngữ gốc trong bước OCR. Không nên dịch tự động ngay trong bước đầu vì các thuật ngữ pháp lý có thể bị biến nghĩa. Cách làm an toàn hơn là trích xuất văn bản gốc, lưu theo từng trang, sau đó tạo một lớp dịch hoặc tóm tắt riêng để người phụ trách pháp chế tham khảo.
Bước 4: Chuyển kết quả sang Markdown và JSON
Theo kho GitHub chính thức của PaddleOCR, PaddleOCR-VL-1.6 hỗ trợ đầu ra có cấu trúc như Markdown và JSON. Với hợp đồng, Markdown phù hợp để con người đọc lại nhanh, còn JSON phù hợp cho tích hợp hệ thống. Một cấu trúc JSON thực tế có thể gồm: metadata, parties, dates, financial_terms, obligations, termination, confidentiality, signatures, stamps, appendices và confidence_score.
Bước 5: Dùng LLM để kiểm tra và gắn nhãn điều khoản
Sau khi có dữ liệu OCR, doanh nghiệp có thể dùng các công cụ AI như ChatGPT, Claude, Gemini hoặc Perplexity để tóm tắt điều khoản, phân loại rủi ro, tạo bảng so sánh giữa các phiên bản hợp đồng hoặc sinh checklist kiểm duyệt. Tuy nhiên, LLM chỉ nên đóng vai trò hỗ trợ phân tích. Những điều khoản liên quan đến trách nhiệm pháp lý, phạt vi phạm, chấm dứt hợp đồng hoặc nghĩa vụ thanh toán vẫn cần chuyên gia kiểm tra.
Bước 6: Human review trước khi lưu trữ chính thức
Một quy trình chuyên nghiệp luôn có bước kiểm duyệt bởi con người. Các trường cần kiểm tra bắt buộc gồm số tiền, ngày hiệu lực, tên pháp nhân, mã số thuế, thời hạn hợp đồng, chữ ký, con dấu và điều khoản phạt. Kinh nghiệm triển khai thực tế cho thấy chỉ cần sai một chữ số trong giá trị hợp đồng hoặc sai ngày hiệu lực, dữ liệu OCR có thể gây rủi ro vận hành đáng kể.
7. Thiết kế schema dữ liệu hợp đồng sau OCR

Schema là khung dữ liệu giúp biến văn bản OCR thành tài sản số có thể tìm kiếm và phân tích. Nếu chỉ lưu toàn bộ nội dung dưới dạng văn bản dài, doanh nghiệp vẫn khó tra cứu nhanh khi cần tìm hợp đồng sắp hết hạn, hợp đồng có điều khoản thanh toán đặc biệt hoặc hợp đồng thiếu phụ lục.
Nhóm metadata
Nên có các trường như mã hợp đồng, loại hợp đồng, ngôn ngữ, ngày scan, nguồn file, số trang, người tải lên và trạng thái kiểm duyệt. Đây là lớp dữ liệu giúp quản trị vòng đời tài liệu.
Nhóm thông tin các bên
Bao gồm tên pháp nhân, địa chỉ, mã số thuế, đại diện ký, chức vụ, email liên hệ và vai trò trong hợp đồng. Với hợp đồng đa ngôn ngữ, nên lưu cả tên gốc và tên chuẩn hóa để tránh sai lệch khi tìm kiếm.
Nhóm điều khoản tài chính và pháp lý
Các trường quan trọng gồm giá trị hợp đồng, đơn vị tiền tệ, VAT, lịch thanh toán, điều kiện nghiệm thu, bảo mật, chấm dứt, bất khả kháng, luật áp dụng và giải quyết tranh chấp. Đây là nhóm nên được gắn cờ kiểm duyệt thủ công vì tác động trực tiếp đến nghĩa vụ doanh nghiệp.
Nhóm bằng chứng hình ảnh
Không nên chỉ lưu text. Với chữ ký, con dấu, bảng phí hoặc phụ lục, hãy lưu thêm tọa độ vùng ảnh hoặc ảnh crop để truy xuất nguồn. Điều này giúp tăng độ tin cậy khi kiểm toán hoặc đối chiếu với bản gốc.
| Nhóm dữ liệu | Ví dụ trường cần trích xuất | Mức độ cần kiểm duyệt |
|---|---|---|
| Metadata | Mã hợp đồng, loại hợp đồng, số trang | Trung bình |
| Các bên | Tên pháp nhân, mã số thuế, đại diện ký | Cao |
| Tài chính | Giá trị, VAT, lịch thanh toán | Rất cao |
| Pháp lý | Bảo mật, chấm dứt, phạt vi phạm | Rất cao |
| Bằng chứng ảnh | Chữ ký, con dấu, phụ lục | Cao |
8. Kiểm thử độ chính xác: Đừng chỉ nhìn benchmark
Kết quả 96,33% trên OmniDocBench v1.6 được nêu trong technical report PaddleOCR-VL-1.6 trên arXiv là tín hiệu rất đáng chú ý, nhưng không nên xem là cam kết tuyệt đối cho mọi tài liệu nội bộ. Benchmark phản ánh năng lực trong điều kiện đánh giá chuẩn; hợp đồng thực tế lại có nhiều biến số như scan lệch, watermark, chữ ký đè lên nội dung, bản chụp thiếu sáng hoặc thuật ngữ chuyên ngành.
Bộ test nội bộ nên có gì?
Doanh nghiệp nên chọn 30-100 hợp đồng đại diện cho nhiều loại tài liệu: mua bán, lao động, NDA, dịch vụ, thuê văn phòng, logistics và hợp đồng song ngữ. Mỗi nhóm nên có file đẹp, file trung bình và file khó. Sau đó tạo bộ ground truth thủ công để so sánh kết quả OCR.
Chỉ số nên theo dõi
- Độ chính xác theo ký tự và theo từ.
- Độ chính xác theo trường dữ liệu quan trọng như số tiền, ngày tháng, tên pháp nhân.
- Tỷ lệ nhận diện đúng bảng biểu và thứ tự đọc.
- Tỷ lệ cần kiểm duyệt thủ công.
- Thời gian xử lý trung bình mỗi hợp đồng.
Góc nhìn chuyên gia: “Với OCR hợp đồng, chỉ số quan trọng nhất không phải là đọc được bao nhiêu chữ, mà là đọc đúng những trường có rủi ro cao: tiền, ngày, bên ký, nghĩa vụ và điều khoản chấm dứt.”
9. Bảo mật, pháp lý và quản trị dữ liệu khi số hóa hợp đồng
Hợp đồng thường chứa dữ liệu cá nhân, thông tin tài chính, điều khoản độc quyền, bí mật thương mại và thông tin khách hàng. Vì vậy, trước khi đưa tài liệu vào pipeline AI, doanh nghiệp cần phân loại mức độ nhạy cảm và xác định môi trường xử lý phù hợp.
Kiểm soát quyền truy cập
Chỉ những người có vai trò liên quan mới nên được xem bản gốc, bản OCR và bản JSON. Hệ thống cần ghi nhận lịch sử truy cập, ai đã sửa dữ liệu, ai đã duyệt và phiên bản nào đang là bản chính thức. Với hợp đồng nhạy cảm cao, nên cân nhắc xử lý nội bộ hoặc môi trường triển khai riêng thay vì đưa dữ liệu lên công cụ chưa được thẩm định.
Vai trò của CentriX.digital
CentriX.digital có thể hỗ trợ doanh nghiệp ở lớp công cụ và hạ tầng số: tài khoản AI, phần mềm bản quyền, Microsoft 365, công cụ năng suất và các giải pháp giúp đội ngũ chuyển đổi số triển khai workflow thực tế. Giá trị không nằm ở việc “mua thêm phần mềm”, mà ở việc rút ngắn khoảng cách giữa ý tưởng số hóa hợp đồng và một quy trình có thể vận hành, kiểm soát và mở rộng.
10. Lỗi thường gặp khi dùng PaddleOCR-VL-1.6 cho hợp đồng và cách khắc phục
Sai thứ tự đọc ở hợp đồng nhiều cột
Hãy kiểm tra layout trước khi xuất dữ liệu cuối cùng, đặc biệt với hợp đồng song ngữ chia hai cột. Nên lưu kết quả theo từng vùng và từng trang để người kiểm duyệt dễ đối chiếu.
Nhầm số tiền, ngày tháng hoặc mã hợp đồng
Cần áp dụng rule validation: định dạng ngày, chuẩn tiền tệ, so khớp tổng tiền và cảnh báo nếu confidence thấp. Các trường này không nên tự động duyệt.
Không nhận đúng bảng phụ lục
Với bảng phức tạp, nên lưu song song ảnh crop vùng bảng và dữ liệu xuất ra HTML hoặc CSV. Người kiểm duyệt có thể đối chiếu nhanh trước khi nhập vào hệ thống.
Dịch sai nghĩa pháp lý
Không trộn lẫn OCR với dịch thuật. Bản OCR nên giữ nguyên ngôn ngữ gốc; bản dịch hoặc tóm tắt chỉ là lớp tham khảo để hỗ trợ đọc hiểu.
11. Gợi ý pipeline triển khai cho doanh nghiệp
Với SME, pipeline tối giản có thể bắt đầu bằng việc upload hợp đồng, chạy PaddleOCR-VL-1.6, xuất Markdown/JSON, kiểm tra thủ công và lưu vào thư mục có phân quyền. Với đội pháp chế hoặc vận hành lớn, nên mở rộng thành pipeline tự động: nhận file từ email hoặc thư mục, phân loại hợp đồng, OCR, trích xuất trường dữ liệu, kiểm tra rule, gửi duyệt và đồng bộ vào DMS, CRM hoặc hệ thống nội bộ.
Một cấu hình thực tế có thể kết hợp Microsoft 365 để quản lý file và phân quyền, ChatGPT hoặc Claude để tóm tắt điều khoản, Perplexity để tra cứu tham chiếu, và dashboard nội bộ để theo dõi trạng thái hợp đồng. Đây là nơi CentriX.digital phát huy vai trò cầu nối giữa công cụ AI, phần mềm bản quyền và hạ tầng làm việc hằng ngày.
12. FAQ: Các câu hỏi thường gặp về PaddleOCR-VL-1.6 và OCR hợp đồng
PaddleOCR-VL-1.6 có dùng được cho hợp đồng tiếng Việt không?
Có thể đưa vào thử nghiệm cho hợp đồng tiếng Việt và hợp đồng đa ngôn ngữ. Tuy nhiên, doanh nghiệp nên đánh giá trên bộ hợp đồng thật của mình trước khi triển khai chính thức.
96,3% accuracy trên OmniDocBench v1.6 có nghĩa là gì?
Đây là kết quả benchmark cho năng lực parsing tài liệu tổng quát, được công bố trong nguồn kỹ thuật và tài liệu chính thức. Nó không bảo đảm mọi file scan nội bộ đều đạt cùng mức chính xác.
Có thể xuất kết quả sang JSON để tích hợp hệ thống không?
Có. Đây là một trong những ứng dụng quan trọng nhất vì JSON giúp đồng bộ dữ liệu với database, CRM, ERP, DMS hoặc công cụ phân tích nội bộ.
PaddleOCR-VL-1.6 có thay thế nhân sự pháp chế không?
Không. Mô hình giúp tăng tốc trích xuất và tổ chức dữ liệu, nhưng các điều khoản quan trọng vẫn cần chuyên gia pháp lý kiểm tra.
Có nên dùng cloud OCR cho hợp đồng nhạy cảm không?
Chỉ nên dùng khi đã đánh giá rõ chính sách bảo mật, mã hóa, vùng lưu trữ, quyền truy cập và điều khoản xử lý dữ liệu. Với dữ liệu rất nhạy cảm, nên cân nhắc triển khai nội bộ.
13. Kết luận: Từ OCR hợp đồng đến hạ tầng tri thức doanh nghiệp
PaddleOCR-VL-1.6 không chỉ giúp nhận diện chữ trong hợp đồng scan. Giá trị lớn hơn nằm ở khả năng chuyển tài liệu phức tạp thành dữ liệu có cấu trúc, có thể tìm kiếm, kiểm duyệt, phân tích và tích hợp vào quy trình vận hành. Với doanh nghiệp có nhiều hợp đồng đa ngôn ngữ, đây là bước nền tảng để xây dựng kho tri thức pháp lý và vận hành hiệu quả hơn.
Để bắt đầu an toàn, hãy triển khai một pilot nhỏ với 30-50 hợp đồng đại diện, xác định schema dữ liệu, đo độ chính xác, thiết kế bước human review và chỉ mở rộng khi quy trình đã ổn định. CentriX.digital có thể đồng hành trong việc lựa chọn tài khoản AI, phần mềm bản quyền và giải pháp hạ tầng số phù hợp, giúp doanh nghiệp biến ý tưởng số hóa thành quy trình làm việc thực tế.



